Run full AI models on your phone, fast. 46 to 57 tok/s on small models with TurboQuant, full chat on 14B+ models, plus on-device vision and image generation. Build AI personas, roleplay with group chat, automate with on-device agents, search your documents, and hear responses with offline TTS, and your AI remembers you across every conversation. Private by default.

Airplane mode on. No Wi-Fi. No data. Still generating.
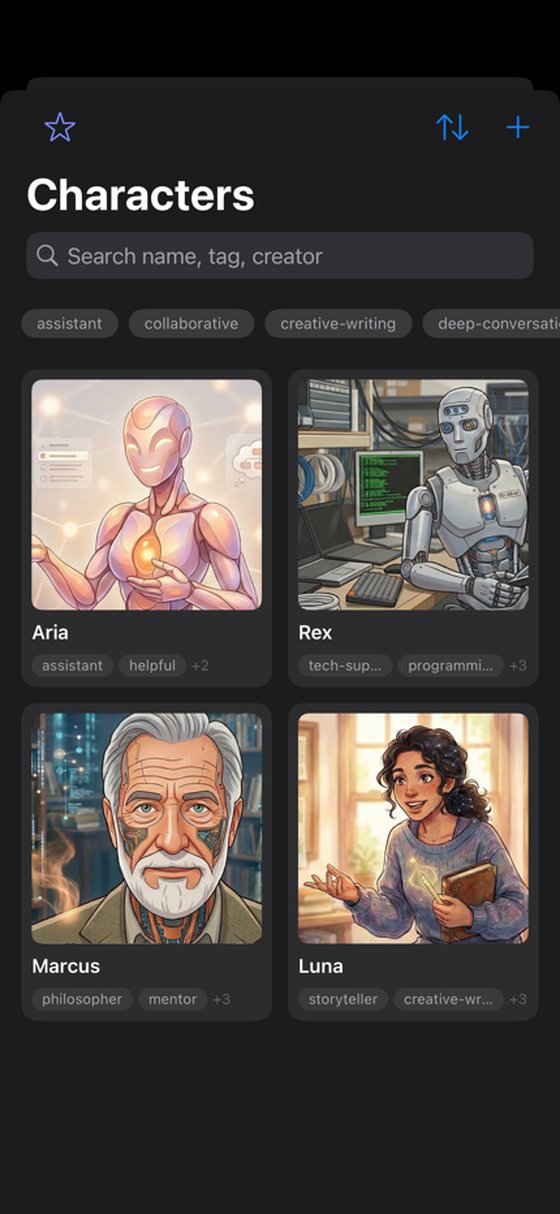
Build reusable personas, bind one per conversation, and import character cards or whole chats from SillyTavern, Layla, and PocketPal. Each character feels different because each one is.
Three inference backends and five GPU paths. TokForge detects your hardware and picks the fastest config automatically. No tuning required.
46 to 57 tok/s on small models with TQ4 TurboQuant. Aggressive GPU quantization that makes lightweight models fly.
Attach PDFs, DOCX, or EPUB files. TokForge summarizes, indexes, and searches them so your AI can answer grounded in your documents, all on-device.
Offline text-to-speech with 11 natural voices and adjustable speed. Powered by Kokoro TTS. No internet, no latency, no data sent anywhere.
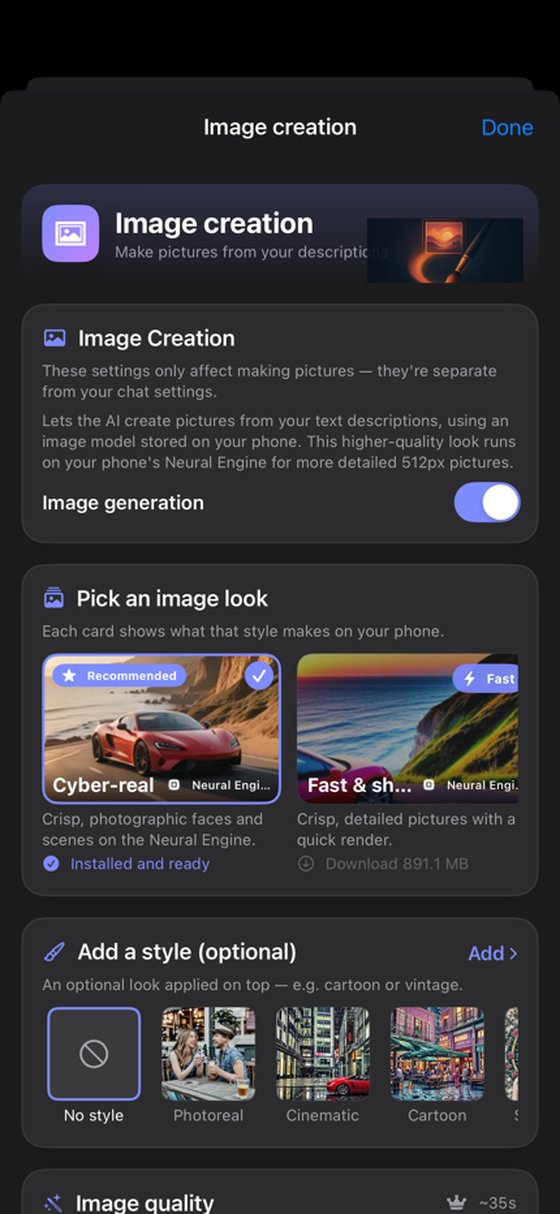
Stable Diffusion runs on your phone. No cloud, no API fees. SD1.5-Turbo, LCM, SD3.x, and an optional NPU Fast tier. Lock a face or subject across images with reference-image identity (IP-Adapter), plus LoRA and multi-subject support.
Attach a photo and ask about it. Qwen3-VL and Gemma-4 Omni run natively; SmolVLM ships as a sidecar for models without built-in vision. Text, vision, audio, and video, all on-device.
Build no-code agents that call tools and run multi-step tasks, all on your phone. Ships with built-in agents and a simple builder, with triggers and bounded loops.
A dedicated roleplay mode with lorebooks, multi-character group chat, and rotation modes. Bring your whole cast into one scene.
The redesigned TokForge, running locally on iPhone & Android: characters, image creation, agents, and more, all on-device.






Real devices. Real tok/s. Reproducible configs.
Vulkan is built, tested, and visible in the app, but it stays lab-only unless a route proves correctness and beats CPU/OpenCL on a specific device/model. MNN Vulkan on Mali-G925 has unresolved numeric corruption (release builds route Vulkan→CPU automatically); MNN Vulkan on Adreno is unstable. The only Vulkan path that ships by default is GGUF Vulkan with cooperative matrix on D9400/D9300 Mali.
| Device | SoC | Model | tok/s | vs CPU |
|---|---|---|---|---|
| OnePlus Ace 5 Ultra | D9400 | 3B Q4_K_M | 16.85 | 3.4x |
| OnePlus Ace 5 Ultra | D9400 | 8B Q4_K_M | 8.07 | ~2x |
Reaches every D9400/D9300 user with zero configuration via BackendCapabilityResolver. Pixel Tensor G4/G3 (Mali-G715) Vulkan unlock with VkPipelineCache cold-compile is in beta validation.
| Device | SoC | Model | Burst tok/s | Reachability |
|---|---|---|---|---|
| OnePlus Ace 5 Ultra | D9400 | Qwen3-8B | 15.3 (peak 20.66) | debug build only |
| OnePlus Ace 5 Ultra | D9400 | Qwen3-14B | 14.1 | debug build only |
Custom NHWC4 GEMV shader on Mali-G925, WGS=64 optimal. These numbers require vulkanG925OverrideEnabled=true (debug-only flag, stripped from release builds) because applyVulkanModelStabilityGuards routes Vulkan→CPU on G925 due to unpatched MNN Vulkan AllShader.cpp corruption. Listed for transparency, not a number a user can hit today. Thermal steady state is ~7 tok/s (GPU power-limit, not model-dependent).
After the libOpenCL stub fix landed in RC20.14 (April 17), every fleet OpenCL number is now ground-truth. On 4 of 5 tested Snapdragon/Dimensity SoCs at 1.7B to 8B, the current CPU recipe with nThreads=2 still ties or beats OpenCL. That's why production defaults route through CPU/OpenCL per device, not Vulkan.
| Device | SoC | Model | Route | Warm tok/s |
|---|---|---|---|---|
| Redmi K70 Ultra | MT6989 | Qwen3.5-0.8B | CPU hot-KV | 40.94 |
| RedMagic 11 Pro | SM8850 | Qwen3-8B | OpenCL | 14.27 |
| Galaxy S20 | SM8250 | Qwen3-1.7B | CPU hot-KV | 14.16 |
| Galaxy S26 Ultra | SM8850 Samsung | Qwen3-8B | OpenCL | ~11.8 |
| OnePlus Ace 5 Ultra | MT6991 (D9400) | Qwen3-8B | CPU hot-KV | 9.67 |
| Redmi K70 Ultra | MT6989 | Qwen3-8B | CPU hot-KV | 8.03 |
| Pixel 10 Pro XL | Tensor G5 | Qwen3.5-9B | CPU hot-KV | 6.01 |
| Galaxy S26 Ultra | SM8850 Samsung | Qwen3-14B | OpenCL | ~5.4 |
| Pixel 9 Pro XL | Tensor G4 | Qwen3-8B | CPU hot-KV | 4.35 |
| Galaxy S26 Ultra | SM8850 Samsung | Qwen3.6-27B* | CPU mmap | loads on 15 GB |
Sustained warm decode (turn 2+ with delta KV reuse). Routes are device-class production defaults via BackendCapabilityResolver + ModelFamilyDefaults. CPU "hot-KV" uses 2-thread Oryon-optimal lane with delta prefill on multi-turn chat. * Qwen3.6-27B (18.9 GB indexed / 17.7 GB effective weights) loads on a 15 GB-RAM phone via the experimental mmap profile. Slow first turn but it loads.
All numbers are post the RC20.14 libOpenCL stub fix (April 17, 2026). Pre-fix OpenCL numbers were silently shadowed by a stub binary and are not comparable.
| Model | MNN OpenCL | GGUF CPU | MNN Advantage |
|---|---|---|---|
| Qwen3-0.6B | 34.8 | 42.7 | −18% |
| Qwen3-1.7B | 27.4 | 16.3 | +68% |
| Qwen3-4B | 20.68 | 9.0 | +130% |
| Qwen3-8B | 14.05 | 5.4 | +160% |
| Qwen3-14B | 8.25 | 2.7 | +206% |
MNN OpenCL overtakes GGUF CPU at 1.7B+ parameters. At 14B, MNN is 3x faster. GGUF wins only on tiny models (<1B) where CPU overhead is negligible. GGUF uses KleidiAI i8mm + futex barrier threading (2T optimal on Snapdragon 8 Elite).
| Model | Quant | Threads | Decode tok/s | Prefill tok/s |
|---|---|---|---|---|
| Qwen3-0.6B | Q4_K_M | 2T | 42.7 | 113.0 |
| Qwen3-1.7B | Q4_K_M | 2T | 16.3 | 43.9 |
| Llama-3.2-3B | Q4_K_M | 2T | 10.1 | 26.6 |
| Qwen3-4B | Q4_K_M | 2T | 9.0 | 20.7 |
| Qwen3-8B | Q4_K_M | 2T | 5.4 | 12.0 |
| Qwen3-14B | Q4_K_M | 2T | 2.7 | 5.8 |
GGUF uses llama.cpp with KleidiAI i8mm acceleration and futex barrier threading. 2 threads consistently outperforms 4 threads on Snapdragon 8 Elite.
Built for privacy-conscious users, roleplay enthusiasts, and developers who want full control.
TQ4 aggressive GPU quantization makes small models absurdly fast: 46 to 57 tok/s on small models, and now coherent on 35B-A3B MoE on Adreno 750/840. Ideal for quick questions, brainstorming, and real-time back-and-forth where latency matters most.
Stable Diffusion runs on your phone. No cloud, no API fees. SD1.5-Turbo on Adreno, SD1.5-LCM on MNN, SD3.x, and an optional NPU Fast tier on rooted devices. Lock a face or subject across images with reference-image identity (IP-Adapter), plus GPU-LoRA, multi-subject masks, and batch generation. Create while in airplane mode.
Attach a photo and ask about it. Qwen3-VL and Gemma-4 Omni run natively; SmolVLM ships as a 500 MB sidecar for models without built-in vision. Text, vision, audio, and video, all on-device.
Create reusable personas and bind one per conversation, then jump into a dedicated roleplay mode with lorebooks, multi-character group chat, and rotation. Import characters and whole chat histories from SillyTavern, Layla, and PocketPal.
Build no-code agents that call tools and run multi-step jobs entirely on-device: bounded loops, triggers, and a batch image-gen agent. Ships with built-in agents and a simple builder.
Browse and download models from Hugging Face inside the app, then see how your phone stacks up on a public phone-speed leaderboard. Hugging Face revision pinning supported.
Three inference engines (MNN, GGUF, Remote API) and multiple GPU paths. TokForge profiles your hardware on first launch and picks the fastest config: Snapdragon, Dimensity, Exynos, or Tensor. You can also connect to a remote server for bigger models.
Attach PDFs, Word docs, EPUBs, or plain text. TokForge indexes and summarizes them, then your AI answers questions grounded in the actual content, all processed on-device, nothing uploaded anywhere.
11 natural voices with adjustable speed via Kokoro TTS, plus the new ZipVoice decoder. Streams per-sentence as the model generates. First audio in seconds, not minutes. Voice input too.
Chat + inference pipeline
TokForge is free on Google Play (Android) open testing and TestFlight (iPhone & iPad) beta. Install directly or join the community to help shape the future of private mobile AI.
No telemetry. No background reporting. Your data stays on your device unless you explicitly opt in.
